Working Smarter at TecSurge with AI
By Joemar S. San Pedro
Cebu, December 10th, 2025. At TecSurge, we previously worked on a project focused on extracting and indexing data from legacy project documentation and drawing files. The challenge was massive with over 700,000 documents, datasheets, vendor drawings, scanned PDFs, and even CAD files in different formats and templates
Each file contained valuable metadata such as document number, title, revision, date, and other relevant attributes — all of which needed to be captured accurately for indexing and digital handover. Initially, we had several employees manually extracting this information and transferring it into Excel files for QA.
To improve efficiency, we developed a .NET program that could extract text from PDF files and automatically export the results to Excel. Due to the wide variation in document layouts and templates, the program often required manual adjustments, such as tweaking bounding boxes or reconfiguring templates. While it saved time, there was still a fair amount of manual intervention needed.

Joemar S. San Pedro, Department Manager of Technical Services for TecSurge, is based in Cebu. With a decade of experience in engineering design for the Plant and Offshore industries, Joemar brings deep expertise in Piping Design and modelling - amassing nine years in the discipline - alongside a year dedicated to E3D development. Over the years, he has cultivated a strong command of complex design environments and multidisciplinary collaboration.
We thought there might be a good opportunity to utilize the growing power of large language model (LLM) technologies to support our work process. By analyzing the document structure and context, an LLM-based program should be more capable of dealing with various challenges such as:
- Blurry or distorted text
- Varying document and drawing layouts
- Mixed languages or embedded symbols
- Scanned documents, or documents which were stored in an image format (TIF, JPEG)
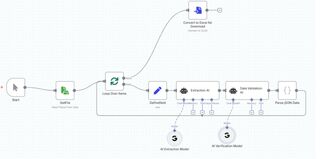
Our earlier program struggled with these variations, often producing unreliable outputs — missing or mismatched metadata fields that required manual cleanup and verification. So, we explored new AI tools and eventually built an automation system powered by two specialized AI agents: one for extraction and another for verification as shown in Figure 1 AI Powered Automation Workflow.
The Extraction Agent
This agent intelligently analyses PDFs — whether digital or scanned — and identifies where key metadata is located. It goes beyond OCR by considering document layout, structure, and context to accurately extract information such as document number, title, revision, and date.
The Verification Agent
Once extraction is complete, the verification agent takes over.
It checks for:
- Spelling accuracy and proper formatting
- Completeness of all metadata fields
- Logical consistency across data points
- Any anomalies or mismatches
If discrepancies are found, the agent automatically corrects or flags them for review. Together, these two AI agents form a closed-loop system — one that doesn’t just extract data but ensures it’s clean, accurate, and ready for use.
Conclusion
What makes this solution stand out is its autonomy — once configured, it can run continuously with no manual supervision. While the technology itself is impressive, I’m most proud of our ability to apply it to solve a real business problem and deliver results more quickly while maintaining our quality objectives. I believe stepping back from doing the work to look for such chances to optimize the process and apply new tools and techniques is part of what makes TecSurge different.
If you are interested in discussing what we can achieve working together, please leave a comment below or contact us today.